


















Nvidia faces lawsuit from authors over alleged copyright infringement in AI models
Nvidia is facing a lawsuit over the alleged use of copyrighted content in its models used to train generative AI tools
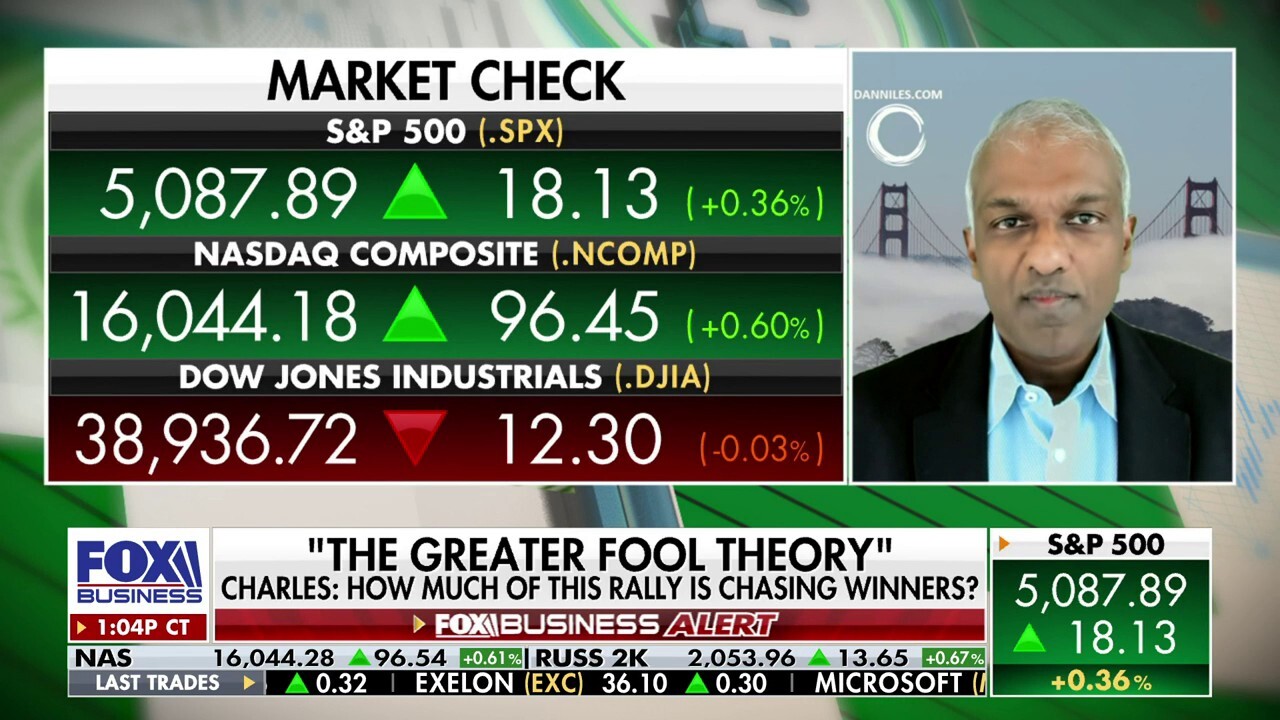
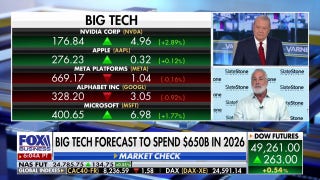
Nvidia is the ‘poster child’ for the AI rally: Dan Niles
Satori Fund senior portfolio manager Dan Niles analyzes the performance of the ‘Magnificent 7’ stocks and reveals some upcoming investment opportunities on ‘Making Money.’
Tech giant Nvidia is facing a lawsuit from a group of authors who said it used their copyrighted works without their permission to train its artificial intelligence (AI) platform NeMo.
Brian Keene, Abdi Nazemian and Stewart O'Nan said their works were included in a dataset of 196,640 books that were used to train NeMo to simulate ordinary written language before it was removed in October "due to reported copyright infringement."
The authors' proposed class action lawsuit was filed Friday night in San Francisco federal court and claims that Nvidia "admitted" it trained NeMo on the dataset, thereby infringing their copyrights. The suit is similar to other lawsuits filed regarding AI copyright infringement.
The lawsuit seeks unspecified damages for people in the U.S. whose copyrighted works helped train NeMo's large language models (LLMs) in the last three years. LLMs are used to power AI tools like NeMo, which Nvidia says is a fast and affordable way to adopt generative AI.
HOLLYWOOD STAR'S AI LAWSUIT FACES MAJOR SETBACKS IN BATTLE AGAINST COPYRIGHT INFRINGEMENT
Nvidia is facing a lawsuit over the alleged use of copyrighted content in its models used to train generative AI tools. (Photo by Ahmet Serdar Eser/Anadolu via Getty Images / Getty Images)
Among the works included in the lawsuit are Keene's 2008 novel "Ghost Walk," Nazemian's 2019 novel "Like a Love Story," and O'Nan's 2007 novella "Last Night at the Lobster."
| Ticker | Security | Last | Change | Change % |
|---|---|---|---|---|
| NVDA | NVIDIA CORP. | 185.41 | +13.53 | +7.87% |
The suit claims the books were included in a data known as "The Pile" that contained a collection of books called "Books3" and Nvidia has admitted to training its NeMo Megatron AI models on The Pile and Books3.
WHAT IS ARTIFICIAL INTELLIGENCE (AI)?
Nvidia is a leading AI chipmaker that has seen its stock surge over the last year. ((Photo by Jakub Porzycki/NurPhoto via Getty Images) / Getty Images)
The NeMo Megatron models were hosted on a website called Hugging Face that included a description of AI models' training dataset, which stated that the model was trained on The Pile. The Pile's Books3 dataset was listed on Hugging Face until October 2023, when the dataset was removed with a message that it "is defunct and no longer accessible due to reported copyright infringement."
Nvidia declined to comment on the pending litigation.
The lawsuit drags Nvidia into a growing group of lawsuits against tech companies over the use of copyrighted content in training AI models, including several filed by writers as well as by the New York Times, which sued ChatGPT-maker OpenAI and Microsoft.
GET FOX BUSINESS ON THE GO BY CLICKING HERE
Nvidia's role as a leading chipmaker for in-demand AI chips has caused its stock to surge by nearly 600% since the end of 2022, giving the company a market value of nearly $2.2 trillion.
Reuters contributed to this report.